An aggregate function computes a single result from multiple input rows. For example, there are aggregates to compute the count, sum, avg, max and min over a set of rows. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement.
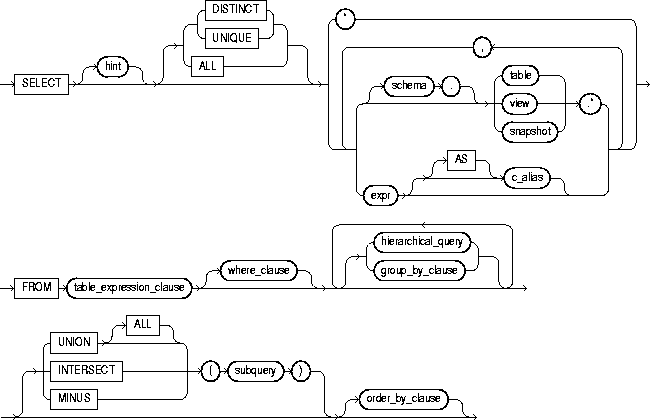
Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected. The expression used to sort the records in the result set.

If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression. DESC sorts the result set in descending order by expression. There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed.

The GROUP BY Clause is utilized in SQL with the SELECT statement to organize similar data into groups. It combines the multiple records in single or more columns using some functions. Generally, these functions are aggregate functions such as min(),max(),avg(), count(), and sum() to combine into single or multiple columns.
Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group. It is better to identify each summary row by including the GROUP BY clause in the query resulst. All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them. We can often use this clause in collaboration with aggregate functions like SUM, AVG, MIN, MAX, and COUNT to produce summary reports from the database. It's important to remember that the attribute in this clause must appear in the SELECT clause, not under an aggregate function.

As a result, the GROUP BY clause is always used in conjunction with the SELECT clause. The query for the GROUP BY clause is grouped query, and it returns a single row for each grouped object. This article explains the complete overview of the GROUP BY and ORDER BY clause. They are mainly used for organizing data obtained by SQL queries.

The difference between these clauses is one of the most common places to get stuck when learning SQL. The main difference between them is that the GROUP BY clause is applicable when we want to use aggregate functions to more than one set of rows. The ORDER BY clause is applicable when we want to get the data obtained by a query in the sorting order. Before making the comparison, we will first know these SQL clauses.

When you build a query, remember that all nonaggregate columns that are in the select list in the SELECT clause must also be included in the group list in the GROUP BY clause. The reason is that a SELECT statement with a GROUP BY clause must return only one row per group. Columns that are listed after GROUP BY are certain to reflect only one distinct value within a group, and that value can be returned.

However, a column not listed after GROUP BY might contain different values in the rows that are contained in a group. The GROUP BY clause groups identical output values in the named columns. Every value expression in the output column that includes a table column must be named in it unless it is an argument to aggregate functions. GROUP BY is used to apply aggregate functions to groups of rows defined by having identical values in specified columns. Table 9-50 shows aggregate functions typically used in statistical analysis.
In all cases, null is returned if the computation is meaningless, for example when N is zero. Using the GROUP BY ClauseThe GROUP BY clause divides a table into sets. This clause is most often combined with aggregate functions that produce summary values for each of those sets. Some examples in Chapter 2 show the use of aggregate functions applied to a whole table.

This chapter illustrates aggregate functions applied to groups of rows. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both.

The most important preconditions for using indexes for GROUP BY are that all GROUP BY columns reference attributes from the same index, and that the index stores its keys in order . It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause. The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results. Aggregates applied to all the qualifying rows in a table are called scalar aggregates. An aggregate function in the select list with no group by clause applies to the whole table; it is one example of a scalar aggregate.

The GROUP BY clause combines similar rows, producing a single result row for each group of rows that have the same values for each column listed in the select list. The HAVING clause sets conditions on those groups after you form them. You can use a GROUP BY clause without a HAVING clause, or a HAVING clause without a GROUP BY clause. The GROUP BY clause defines groups of output rows to which aggregate functions can be applied.

The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns. This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT.

You must use the aggregate functions such as COUNT(), MAX(), MIN(), SUM(), AVG(), etc., in the SELECT query. The result of the GROUP BY clause returns a single row for each value of the GROUP BY column. If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). The HAVING clause filters group rows created by the GROUP BY clause.
The HAVING clause is applied to each group of the grouped table, much as a WHERE clause is applied to a select list. If there is no GROUP BY clause, the HAVING clause is applied to the entire result as a single group. The SELECT clause cannot refer directly to any column that does not have a GROUP BY clause. The EXCEPT operator is used to exclude like rows that are found in one query but not another. To use the EXCEPT operator, both queries must return the same number of columns and those columns must be of compatible data types. Aggregate functions can be used only in the select list or in a having clause.
FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. If you don't use GROUP BY, either all or none of the output columns in the SELECT clause must use aggregate functions. If all of them use aggregate functions, all rows satisfying the WHERE clause or all rows produced by the FROM clause are treated as a single group for deriving the aggregates.

The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM(). In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. The above query includes the GROUP BY DeptId clause, so you can include only DeptId in the SELECT clause. You need to use aggregate functions to include other columns in the SELECT clause, so COUNT is included because we want to count the number of employees in the same DeptId. Another extension, or sub-clause, of the GROUP BY clause is the CUBE.

Which Sql Query Must Have Must Have A Group By Clause The CUBE generates multiple grouping sets on your specified columns and aggregates them. In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on of your table, SQL returns groups for all unique values , , and . ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions.
Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. For each of these hypothetical-set aggregates, the list of direct arguments given in args must match the number and types of the aggregated arguments given in sorted_args.
Unlike most built-in aggregates, these aggregates are not strict, that is they do not drop input rows containing nulls. Null values sort according to the rule specified in the ORDER BY clause. Aggregate functions are functions that take a set of rows as input and return a single value. In SQL we have five aggregate functions which are also called multirow functions as follows. Optionally it is used in conjunction with aggregate functions to produce the resulting group of rows from the database. Otherwise, each column referenced in the SELECT list outside an aggregate function must be a grouping column and be referenced in this clause.

All rows output from the query that have all grouping column values equal, constitute a group. In this query, all rows in the EMPLOYEE table that have the same department codes are grouped together. The aggregate function AVG is calculated for the salary column in each group. The department code and the average departmental salary are displayed for each department. Here, you can add the aggregate functions before the column names, and also a HAVING clause at the end of the statement to mention a condition.

While the first query is not needed, I've used it to show what it will return. This statement will return an error because you cannot use aggregate functions in a WHERE clause. WHERE is used with GROUP BY when you want to filter rows before grouping them. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses. If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions.

It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year. The SUM() function returns the total value of all non-null values in a specified column.
Since this is a mathematical process, it cannot be used on string values such as the CHAR, VARCHAR, and NVARCHAR data types. When used with a GROUP BY clause, the SUM() function will return the total for each category in the specified table. The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions.

HAVING and WHERE are often confused by beginners, but they serve different purposes. WHERE is taken into account at an earlier stage of a query execution, filtering the rows read from the tables. If a query contains GROUP BY, rows from the tables are grouped and aggregated.
![]()
After the aggregating operation, HAVING is applied, filtering out the rows that don't match the specified conditions. Therefore, WHERE applies to data read from tables, and HAVING should only apply to aggregated data, which isn't known in the initial stage of a query. The GROUP BY clause causes the rows of the items table to be collected into groups, each group composed of rows that have identical order_num values . After you form the groups, the aggregate functions COUNT and SUM are applied within each group. The aggregate functions do not include rows that have null values in the columns involved in the calculations; that is, nulls are not handled as if they were zero.

HAVING Clause is used as a conditional statement with GROUP BY Clause in SQL. WHERE Clause cannot be combined with aggregate results so Having clause is used which returns rows where aggregate function results matched with given conditions only. The MYSQL GROUP BY Clause is used to collect data from multiple records and group the result by one or more column. You can also use some aggregate functions like COUNT, SUM, MIN, MAX, AVG etc. on the grouped column. Adding the DISTINCT keyword to a SELECT query causes it to return only unique values for the specified column list so that duplicate rows are removed from the result set. Since DISTINCT operates on all of the fields in SELECT's column list, it can't be applied to an individual field that are part of a larger group.

The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. The only aggregate functions used in the select list are MIN() and MAX(), and all of them refer to the same column. The column must be in the index and must immediately follow the columns in the GROUP BY. In some cases, MySQL is able to do much better than that and avoid creation of temporary tables by using index access. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group. This statement is used to group records having the same values.

The GROUP BY statement is often used with the aggregate functions to group the results by one or more columns. While all aggregate functions could be used without the GROUP BY clause, the whole point is to use the GROUP BY clause. That clause serves as the place where you'll define the condition on how to create a group. When the group is created, you'll calculate aggregated values.




